运一堆没用的手册到焚烧炉里。

如果只有一只地鼠,这需要很长时间。

更多的地鼠还不行;他们需要更多的小推车。

这样快多了,但在装运处和焚烧炉处出现了瓶颈。
还有,这些地鼠需要能同时工作。
它们需要相互通知。(这就是地鼠之间的通信)
消除瓶颈;让他们能真正的相互独立不干扰。

这样吞吐速度会快一倍。
并发组合两个地鼠的工作过程。
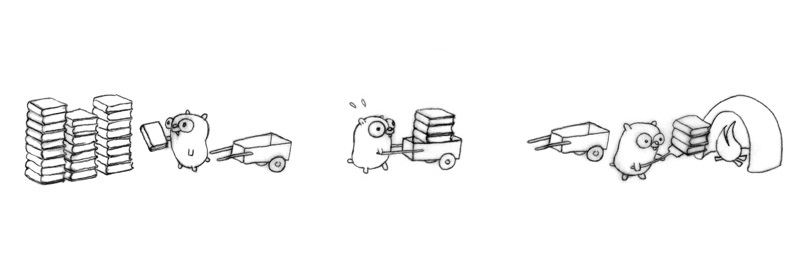
三只地鼠在工作,但看起来工作有些滞后。
每只地鼠都在做一种独立的工序,
并且相互合作(通信)。
增加一只地鼠,专门运回空的小推车。
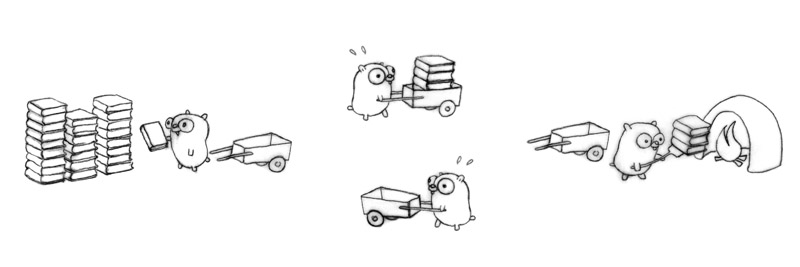
四只地鼠组成了一个优化的工作流程,每只只做自己一种简单的工序。
如果任务布置的合理,这将会比最初一个地鼠的工作快4倍。
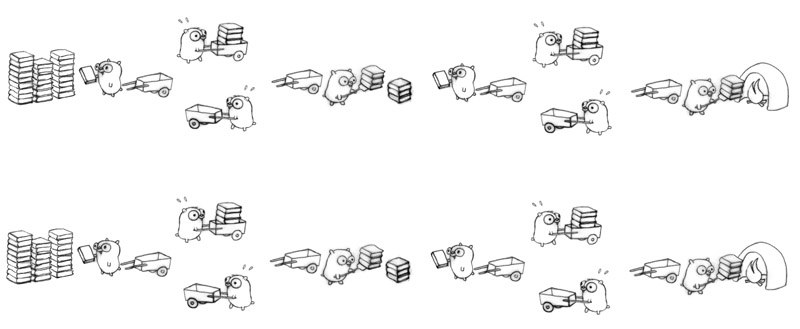
现在我们可以让并行再多一倍;按照现在的并行模式很容易实现这些。八个地鼠,全部繁忙。
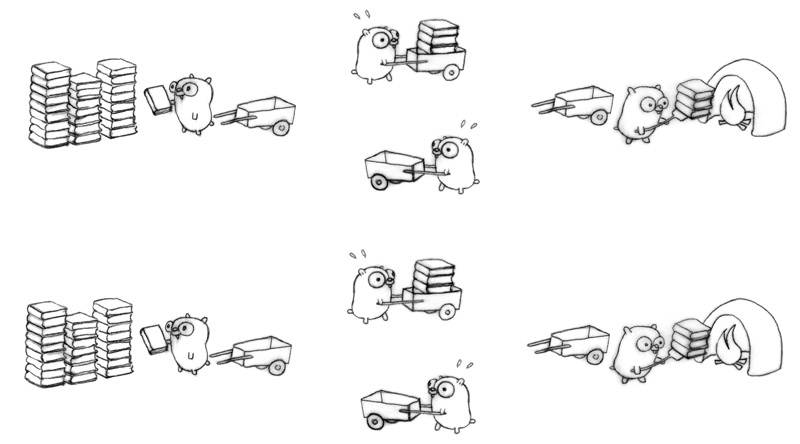
请记住,只有一个地鼠在工作(零并行),这仍然是一个正确的并发的工作方案。
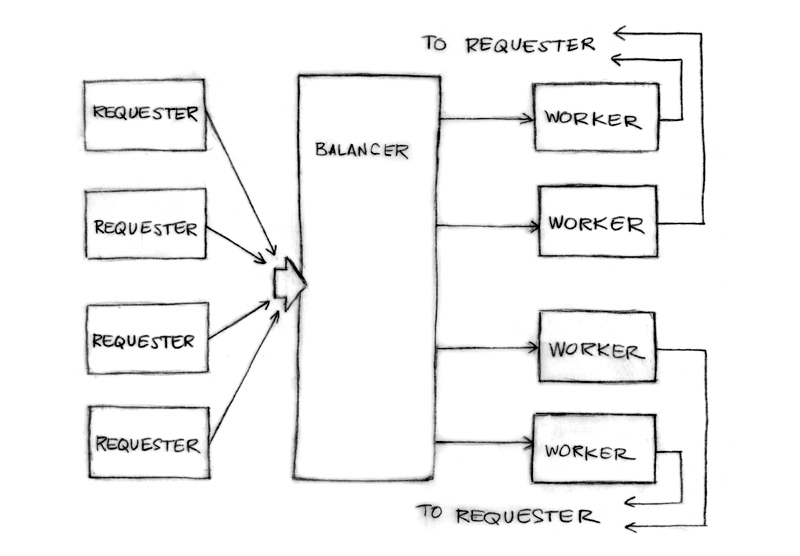
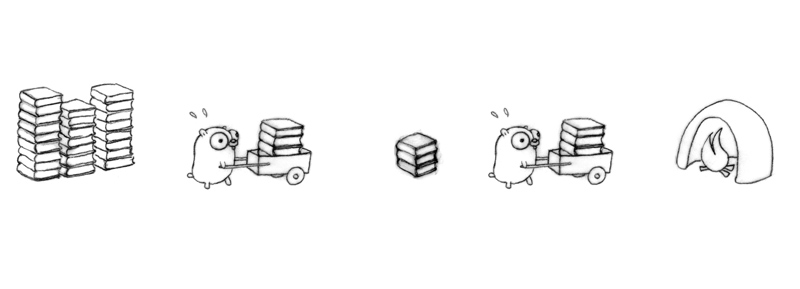
现在我们换一种设计来组织我们的地鼠的并发工作流程。
两个地鼠,一个中转站。
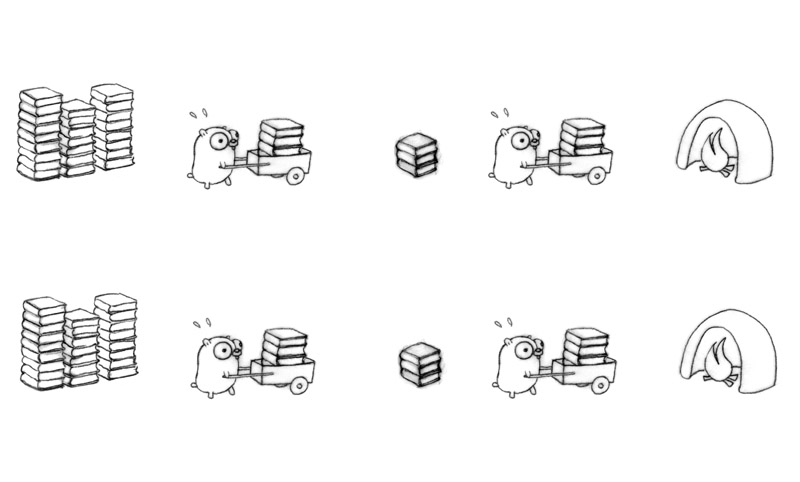
更多的并发流程能获得更多的吞吐量。
在每个中转站之间都引入多个地鼠并发的模式:
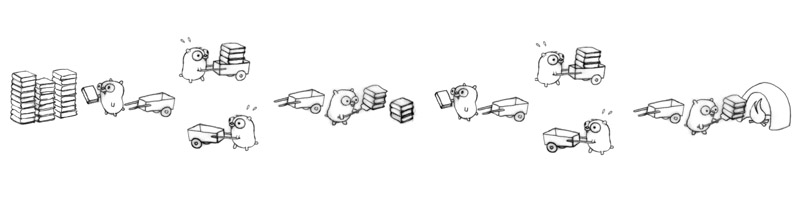
使用这种技术策略,16个地鼠都很繁忙!